

How Database Indexing Makes Your Query Faster in a Relational Database - The Complete Guide
- Gourav Dhar
- Nov 22, 2022
- 12 min read

Updated: Dec 9, 2022

Imagine you are in a library that has thousands of books and you have a book titled "Find me". The problem is that all the books are arranged based on their serial number. You would have to go through each book serially and check their name until you find the book you are searching for. You would have to spend a couple of hours to find that book. Now imagine that the librarian gives you a list of all the books sorted alphabetically and the corresponding serial number of the book. How long do you think it will take you to find that book? A couple of minutes, right?
With the list that the librarian gave you, your search time was reduced from hours to minutes. Now think of this library as a table in a database and then this list would be the database index.

If you are a software developer, a database engineer, a system architect, or a computer science student, you would need to design and develop your system such that it is efficient and optimized. If you don't know how database indexing works and want to know more about it and the good practices that need to be followed while creating new indexes, this blog is for you.
Let's dive right in -
What is Database Indexing?
A database index is a data structure that improves the performance of database queries by making them faster. The database index makes the data easier to retrieve and speeds up data access. This entire process is called database indexing. These database indexes are actually data structures that store the search keys in a way that they can be easily searched.
Databases like MySQL and PostgreSQL also have a system of caches and parallel searches to make querying faster and more optimized.
Data Structures that Database Index use
B-TREE and HASH are the 2 most common database indices that are used. Let's look at them.
B-TREE Index
B-TREE is the most popular and default index type in most relational database management systems. The `B` in 'B-TREE` stands for (Balanced).
There are mainly 2 goals that this index data structure takes care of -
Facilitate the ability to fetch data faster and more efficiently
Store the data in a sorted manner
The B-TREE index makes use of the tree data structure to sort the data and allow querying faster. You may be aware of how the binary search tree works. The search operation in a B-TREE is similar to what happens in a balanced binary search tree but with few differences.
Each node in a B-TREE has a range of values.
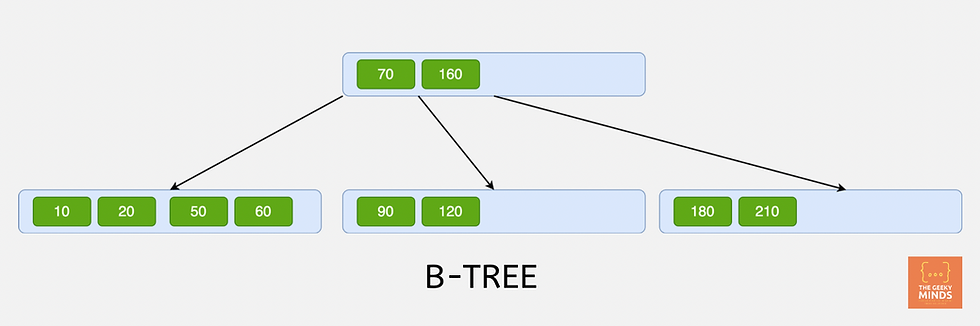
As it is clear from the diagram above, each node has values from d and 2d, where d is the depth of the B-TREE. Hence, the number of child nodes, each node has, turns out to be 2d+1.
All the values to the left of a value are lesser than the node value. Similarly, all values to the right are greater than the node value.
The search operation is similar to how we would search in a Binary Search Tree. Inserting and deleting operations in a binary search tree don't create new nodes or delete existing nodes. This means that there will be empty space in the nodes. As a result, creating a B-TREE requires more disk space.
The process of adding a new value involves checking the leaf nodes, if space is there, then add it. Else check the parent node, if space is there. There can be cases where you would need to split a node into 2 new nodes if any overflow happens.
Deleting a value is just the opposite of how adding a value works. If deleting a value causes underflow, we will merge 2 nodes to combine into a single node.
When this B-TREE is used as a data structure for the database index, we use values of the index to create this B-TREE and each value also holds the pointer to the row to which this value belongs. In short, each value will contain 3 things -
Index value
Pointer to the row in the table this value points to
Pointer to the child nodes
If we use B-TREE as a database index, we can use this data structure to perform operations like
equality operations (= or <=>)
query for a range (>, <, >=, <=, BETWEEN)
LIKE operation
We can create an index on more than one column. For example, if we make an index on a pair of columns (first name, last name), we are able to search using either attribute or both. The index will also work when only one of the attributes is searched.
From the B-TREE data structure, it should be evident that this data structure will work best when the most searched data is closer to the root node.
B+ TREE Index
The InnoDB database engine, which is also the most common engine if you are using MySQL uses this B+ TREE as the data structure to store indexes.
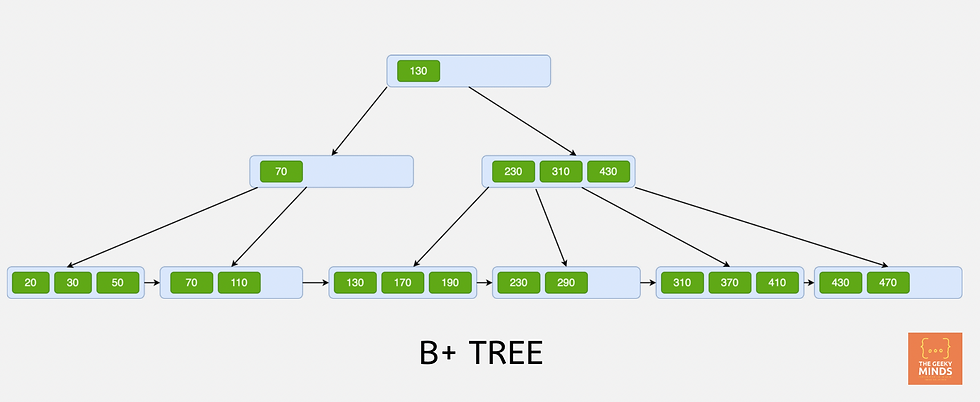
The B+ TREE is similar to the B-TREE except for these differences:
In a B-TREE, each value is unique whereas, in a B+TREE, there are repeated values in the root and subsequent child nodes.
The internal nodes don't store the pointers to the actual rows in the database, they store just the values and the pointer to the next node. The benefit of this is reduced space for storage, hence one block can have many more values, which increases the number of branches and reduces the depth. Less depth means fewer read/write operations.
The leaf nodes are linked in a B+TREE, which means that a full-row scan can be done in one go. This improves performance if a query returns a range of results. The leaf nodes also have a pointer to the actual row in the table.
In a B+ Tree, you have to traverse the entire depth of the tree, till the root to fetch a value from the table, as only the leaf nodes store the pointers to the rows.
To know more about B+ TREE, check out this.
Hash Index

The Hash Index works exactly the same as the hashing technique. The value of the indexed column is passed through a hash function. This hash function pointed to a memory bucket where this row or pointer to this row is stored. One memory bucket can store multiple rows or pointers to the row. When you want to search for a value based on this index, pass it through the above hash function which will then return the address of the bucket where this row is stored. You iterate through all the stored addresses to get the result you are looking for.
Hash indexes are really good when querying for equality with the = operator. But it fails to work for cases where we are comparing or when the result needs to be a range of values.
Downloading sample database for experiments

To run experiments for this blog, I have downloaded the Sakila Database which can be downloaded from here. You can import the .sql files into your MySQL database. If you want instructions on how to do that, refer to this link. For this blog I will be using the film table, it has 1000 rows in it. I am using MySQL workbench to run my queries.
This table by default has indexes present. I have removed the indexes from the table to compare the time taken for queries with and without indexes.
Well, the `film` table has only 1000 rows. A production database has many more entries. So I will need to populate this table with more rows. I have written a script to do this.
In line number 46 of the above script, you can enter the number of rows you want to add to this database. My table has now a total of 65534 entries. It's still less than industry standards but it will suffice for the experimenting purpose.
Diving into the database index parameters
Every table in MySQL will have a primary key mandatorily. All the primary keys by default are indexed by the database. The tables in the above database have columns indexed. I will run this command to see existing indexes on the table named actor
> show indexes FROM sakila.actor;This gives me :

There are 2 indexes present in this table. One is the Primary Key. The other was created separately. The output has the following columns :
Table: Contains the table name that this index belongs to
Non_unique: Denotes whether the index is unique or not. A value of 0 indicates that the search keys in this index are unique
Key_name: This is the name of the index which was given. The value of "Key_name" is always PRIMARY for a primary key index
Seq_in_index: This denotes the sequence number of the column in an index. A single index can be comprised of multiple columns. The sequence number starts from 1 and will be assigned to the columns in the same order they were added to the index.
Column_name: This is the column name this index belongs to
Collation: Collation denotes how the search keys will be sorted. "A" stands for Ascending and "D" stands for descending. If "NULL" is stored, it means that the columns are not sorted.
Cardinality: This indicates the number of unique values present in the column.
Sub_part: If a column is partially indexed, "Sub_part" will store the number of bytes that are indexed. If it is "NULL", it means the entire column is indexed.
Packed: Indicates how the key is packed; NULL if it is not.
Null: Indicates if the search key can contain NULL values or not. If the field is blank, it means it does not contain NULL values.
index_type: Indicates which data structure has been used for the index. The possible values are: BTREE, HASH, RTREE, or FULLTEXT
Comment: Contains information about the index
Index_comment: Contains index-specific comments the user may have added
Performance testing with database index
My SQL by default uses the B-TREE index. I will use the same for my experiments. I will test all the queries with and without indexing and compare their speed. After all, this is what really matters!
First, we will need a way to calculate the time taken by a query to get executed. The way to do that would be
ROUND(UNIX_TIMESTAMP(CURTIME(4)) * 1000) - will give us the current time in milliseconds
Check existing indexes
> show indexes FROM sakila.film;
There's an index on the column named `film_id` which is the primary key. The primary key will always be indexed. You can see, the index type is BTREE.
Searching by the indexed value

Time taken is 4 milliseconds. It should be very less and matches our expectation.
Searching the "non-indexed" value by the indexed column
Time taken is 9 milliseconds, slightly more than the previous case because this time I was querying for a field not present in the search key.
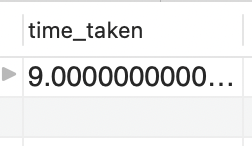
If I run the query again, the time taken will reduce. This is because this time the database returned the from the cache.

In the above two queries, we are searching based on the film_id which is actually the primary key and it is by default indexed. To fetch the result, MySQL is not going through all the entries in the table, but it is making use of the index.
You can run the EXPLAIN statement to see how MySQL approached this query. The output of the EXPLAIN statement returns the following parameters. You can know more about it here.
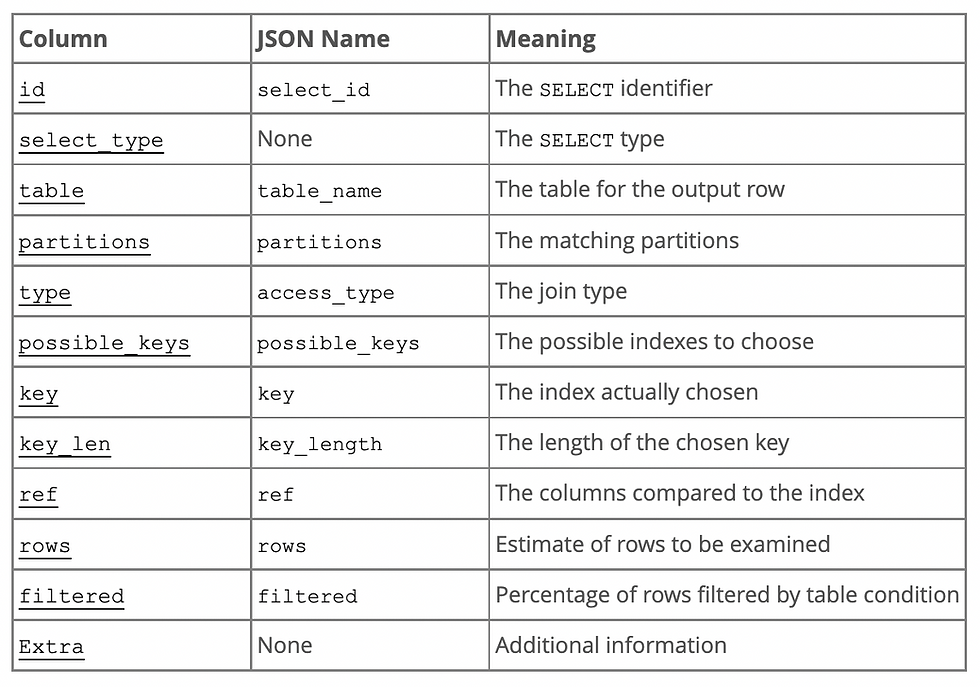
> explain SELECT * FROM sakila.film where film_id = 65535;
The output shows that the type is const, which means that at most 1 row was examined. O(1) time complexity. Since this is the primary key, the fetch type will be const as it is stored in sorted order in the memory. The rows field also indicates that only 1 row was looked at.
Searching by the "non-index" column
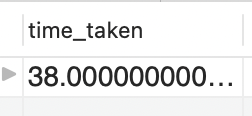
The time taken in this case is 38 ms which is much higher than when we searched using the id
On running the explain query
> explain SELECT film_id FROM sakila.film where title='WATERFRONT DELIVERANCE';I get -

Since this "title" column was not indexed, MySQL actually went through 65025 rows before fetching this result. The "rows" column indicates this. This is a lot. This explains the time 38ms that it took.
Using "LIKE" to search on the "non-index" column
The time taken in this case is 57 ms which is again much higher than when we searched using by string comparison
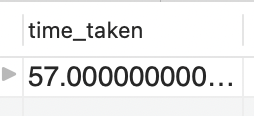
The reason it took so much time is that MySQL went through each string field and compared the string.
I will run explain query
> explain SELECT film_id FROM sakila.film where description like '%elieveable Yarn of a Boat And%';I get -

The output of "explain" is similar to the previous case.
Group By on a non-indexed column
The above operation took 51 ms.
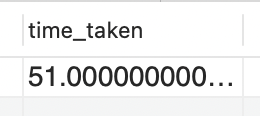
The explain query
> explain SELECT release_year,COUNT(*) FROM sakila.film GROUP BY release_year;gives me

Deleting entries from the table

Now I will create an index on the non-indexed columns used above and see the difference in time.
How to create a database index?
I will create an index on these columns. The query to do that is
> create index title on film(title)
> create index release_year on film(release_year)You can also create an index with multiple columns if you feel that it is something by which you will be querying often.
> show indexes FROM sakila.film;gives me -

I will re-run all the above search queries and then compare the difference
The query
> SELECT film_id FROM sakila.film where title='WATERFRONT DELIVERANCE';took 9ms
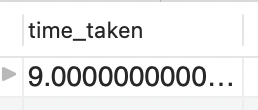
The query
> SELECT release_year,COUNT(*) FROM sakila.film GROUP BY release_year;took 28ms

Running the explain query tells us that MySQL is using an index to fetch the result. It will also tell us the name of the index which is used to fetch the result.

The query
> SELECT film_id FROM sakila.film where title like '%ni4id6ft7%';took 36ms
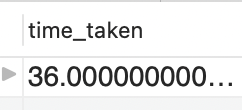
The explain query -
explain SELECT film_id FROM sakila.film where title like '%ni4id6ft7%';tells that index was used to perform this query

This time the database actually used an index to fetch the result. Even though the number of rows the table examined is still 65k, the query time was faster because of the B-TREE data structure index which was used by the MySQL database engine.
The delete operation took 4 milliseconds, which is higher than before.
Tabulate the findings
I will tabulate the above data
Operation | Time taken without indexing (in ms) | Time taken after indexing (in ms) | % of time improved after using index |
Simple search query | 38 | 9 | 76.31 |
Group by query | 51 | 28 | 45.09 |
Search using LIKE | 57 | 36 | 41.17 |
Delete rows | 2 | 4 | -100 |
From the above data, it can be seen that introducing a database index had a very great impact on the query speed of fetching data, but it negatively impacted the DELETE operation. It was actually expected. The database would also need to delete the entry from the data structure used for indexing, which added to the increase in time of the deletion operation. Similarly, the INSERT operation will also take more time.
The Right Way to Add Database Index
Here's the situation, you want to improve the database query fetch time, but at the same time don't want the update/insert/delete operations to be slow. Adding database indexes will definitely introduce some delay in the update/insert/delete operations, the key is to maintain a balance between these two. You need to keep in mind the following things so that adding database indexes does not negatively impact your query performance:
Index by usage not by columns: As a developer, you should only index columns that are used in a lot of frequent queries. You should not create indexes based don't the possibility of them being used in future
Index to avoid sorting (GROUP BY, ORDER BY): The columns on which ORDER BY or GROUP BY queries are called are usually sorted by the database. It's good to create indexes for these columns too. It prevents an extra sorting operation by the database.
Be aware of the negative implication of update/delete operations: After creating an index, it's a good idea to see if the insert/delete operations are not negatively impacted by a lot of margin.
Types of Database Indexes
The database indexes can be divided into three types:
Single Level Indexing
Single Level Indexing has a concept similar to the "table of contents" in a book. It can be divided into 3 subcategories-
Primary Indexing
Secondary Indexing
Clustering
1. Primary Indexing
When an index is created using the primary key of the table, it is called primary indexing. Since the primary key of a table is unique, not null, and possesses a one-to-one relationship with every entry in the table, all these properties of the primary key pass onto this primary indexing. In primary Indexing, the search keys are sorted, so fetch is highly efficient.
2. Secondary Indexing
An index in a table that is created in a table using a key that is not a primary key is called secondary indexing. Adding a secondary index makes the database querying more efficient, but unlike primary indexing, in secondary indexing, the values point to rows of the table, and the actual rows are not sorted in any order. This is also called non-clustered indexing.

3. Clustered Indexing
When the indices point to a bucket or block of memory and not a particular entry in the database, it is called clustered indexing. The search keys in clustered indexing are sorted and may or may not be unique.
Ordered Indexing
In this, the data is stored in a sorted manner so that the search is efficient. This can be further divided into 2 categories
Dense Indexing
Sparse Indexing
1. Dense Indexing
In dense indexing, the database stores a search key for each and every column in the table. Imagine the way the primary key is stored as an index and replicate it to overall columns, you would get dense indexing. The search is definitely faster but requires lots of storage space
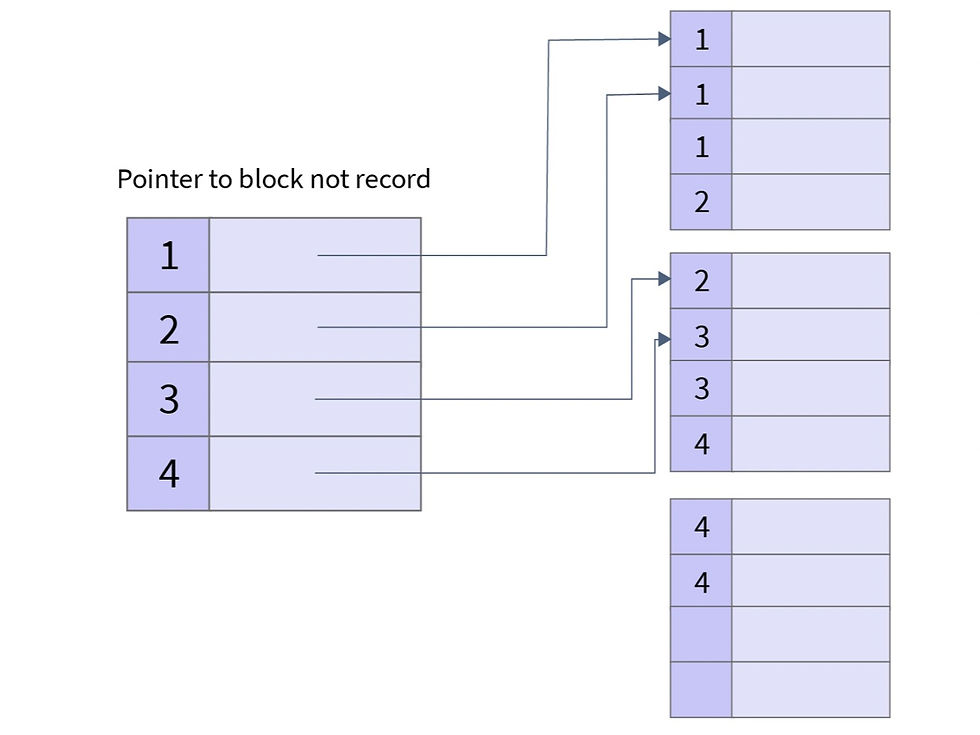
2. Sparse Indexing
In sparse indexing, we index some of the columns and the search keys point to another block where again search operation may or may not be performed. Since we have to search multiple times, it is slower than dense indexing but consumes less space.
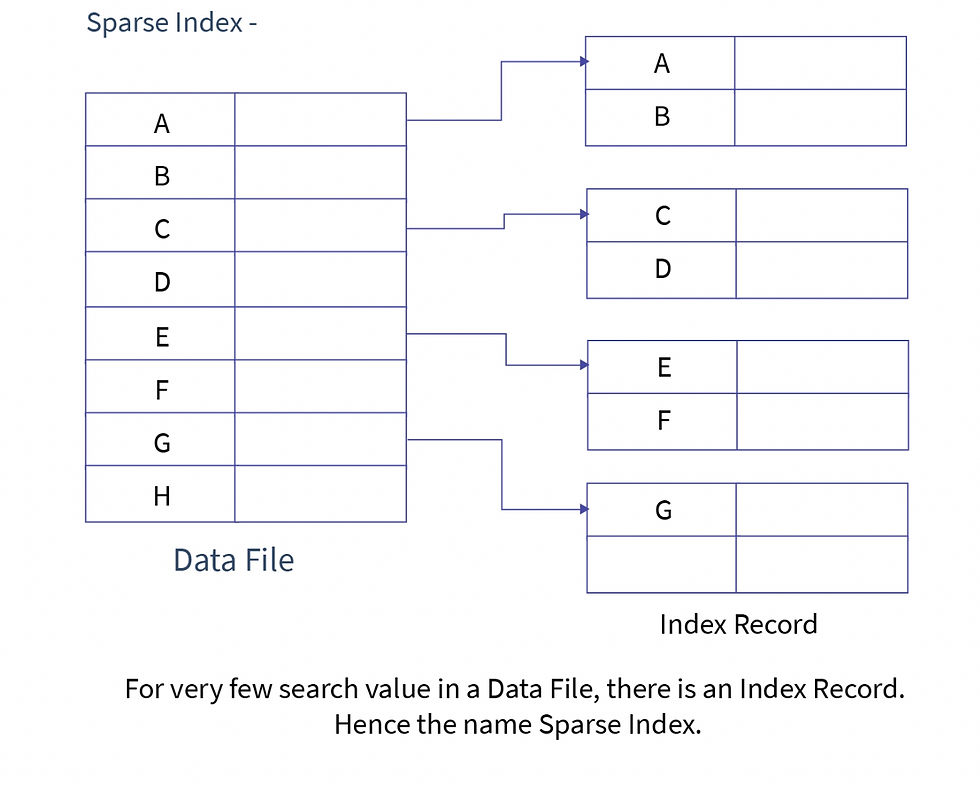
Multi-Level Indexing
In single-level indexing, all the data is stored in one place and it is not physically possible to store all these data in a single memory block. So multi-level indexing was introduced to divide the data into smaller blocks and the size of the outermost block was small enough to be stored in the main memory
Conclusion: Your Data is Now Ready for Fast Queries!
Indexing can improve the performance of your queries by a lot. It helps in faster query results and quicker data retrievals. Indexing also helps in the performance of ORDER BY and GROUP BY queries which require internal sorting. Indexing also helps in better CPU Utilisation to perform the query. ith all these benefits, indexing requires more storage space, and the insert/delete/update operations are negatively impacted. As a software developer, it is your responsibility to see what best works for your system and implement it.

And that's a wrap! Hi, I am Gourav Dhar, a software developer and I write blogs on Backend Development and System Design. Subscribe to my Newsletter and learn something new every week - https://thegeekyminds.com/subscribe
Frequently Asked Questions (FAQs)
When to use Database Indexing?
If you are performing frequent queries on a column, it's a good idea to create an index for that column.
Where is the database index stored?
The database index is stored in a data structure in memory on the disk. B+ Tree is the most common data structure used to store database index.
Does the database index require additional storage?
When you create a database index, an additional storage space is required to store this data structure which was created as part of the database index creation.
All the code used in this blog can be found here



_edited.png)







































































If you are searching for southwest airlines what terminal at sky harbor, Southwest Airlines operates from Terminal 4 at Phoenix Sky Harbor International Airport. Travelers looking up southwest airlines what terminal at sky harbor often need quick information about check-in locations, baggage services, departure gates, and arrival procedures. Terminal 4 offers a wide range of passenger amenities, including restaurants, cafés, retail stores, and comfortable waiting areas. It is the primary terminal for Southwest Airlines flights at the airport. Knowing southwest airlines what terminal at sky harbor before your trip can help you navigate the airport efficiently and avoid unnecessary delays.
Database indexing plays a big role in making queries faster in relational databases it helps the system find data quickly without scanning every row this guide clearly explains how indexes improve performance and efficiency for students learning databases it is very helpful I recently got an assignment on this topic in my university and needed help to complete it on time so I used online exam helpers they really made my work easier and helped me understand the concept better while meeting deadlines
Discover love and fantasy in your language with antarvasna marathi, where each story blends emotions, passion, and bold imagination that awakens the hidden desires within.
Your breakdown of database indexing is really clear and helpful it reminded me of the times I tried to organize sprawling ideas in my drafts but couldn’t quite get the logic to hold. That’s when I decided to hire a ghostwriter someone who brings structure to complexity, smooths the transitions, and helps the underlying idea shine through without losing your original voice.
Reading the “Complete Guide to Database Indexing” brought me back to nights when I had a mountain of research and queries to sort through and everything felt slow and messy. In those moments Ranked Design came into mind: not as something to do the work for me, but as a structure to help map my findings, sharpen my logic, and organize data so it hits clean, clear, and fast.