

APIs and How to design them — All you need to know !
- Gourav Dhar
- May 2, 2022
- 5 min read

Have you created a service and want others to use it? Well!!! Apis are the way to do it.

What is an API?
Suppose you have written a program that performs a task (maybe takes an input and returns an output based on it). You would want a way for other people to use your program — You need APIs for this purpose.
API stands for Application Programming Interface, which is a software interface between external users or other services and your program. We can expose API endpoints on the internet through which other applications can interact with our program.
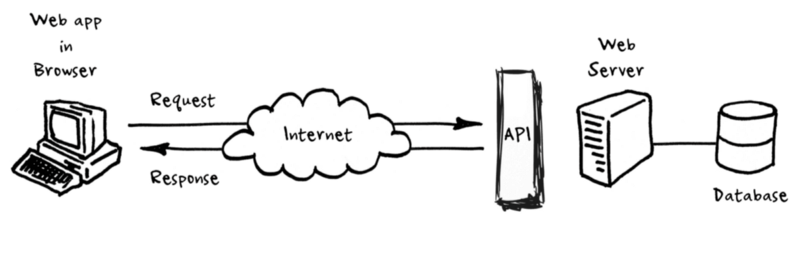
Source: www.altexsoft.com
Designing good APIs
There’s no one right set of characteristics. Whatever design serves the purpose in an efficient manner is a “good API design”.
As a software developer, I would want the APIs to have the following set of characteristics which would ensure consistency, security, and efficiency in my system.
SRP (Single Responsibility Principle)

Source: LearnStuff.io
Ensure each API has a single responsibility. This makes the operation performed atomic and our database is consistent with what the clients expect. This way the client knows that if the API fails or returns an exception, then no part of the operation was performed. It reduces ambiguity.
Let’s take an example — Suppose we want to create a user and assign a label to it. If we use a single API to execute the operations and the API fails and returns an exception, there would be confusion whether the user was created and an exception occurred while creating the label, or exception was returned while creating the user and no user was created. So it is better to create 2 separate APIs, one for creating users and the other to update parameters/assign labels to users.
Naming the API
Name the APIs so that it becomes easy for the clients to guess the purpose of the API. The type of request (GET, PUT, POST, DELETE) adds context to the naming as well. This way if your server has a bunch of APIs exposed, it becomes easy for the client to manage the APIs while using them. Also, it makes debugging easier.
For example, if you want to get details of a user, you could name the API as
GET - /api/user/{userId}Similarly to delete the user you could name it as
DELETE — /api/user/{userId}Abstraction
Return only what is needed.
Sometimes you may be convinced to return extra information through your API maybe by apprehending certain requirements for the future. Trust me it’s not a good idea! (A lot of times it will happen that those requirements don’t come up or you will end up creating a separate API for it for some reason).
You don’t want to expose certain information which can be exploited by hackers to get into your system. Be careful!
Also exposing only what is needed is a neat way to present, creates less confusion, and also reduces coupling in some cases.
Returning less data — reduces response time and saves internet bandwidth. (And makes surfing easy for everyone!)
Logging
Logging API name, request parameters, response time is a good practice that helps to debug issues and maintain your program.
It is also important that you accidentally don’t log user sensitive information, like email, passwords, credit card details, etc. which may be received as part of the API request, and can be a probable security vulnerability.

Validate User Roles / Permissions
Add user role validations to APIs. It is obvious right!, you don’t want the regular users to have access to APIs meant for Admin.
Throw Custom Exceptions
In case your API fails — due to some internal function failure or a database network call, maybe due to invalid input or whatever, it is a good practice to throw a custom exception message along with the exception. (Maybe create a custom Exception class).
This helps a lot while reading logs and debugging issues. The client also gets an idea of what is going wrong.
The way to do this would be to identify probable scenarios where the API is likely to throw an exception, for example when a client is trying to access information he/she is not entitled to or maybe if the client requests to modify user details which don’t exist.
Response Time
The less response time the better! — Obvious right.

Make sure to place the endpoint on the correct micro-service which would optimize the number of external calls made to other microservices. Also while making database calls, try to reduce the number of calls (by maybe fetching all the data together or other ways).
Another way would be to receive extra parameters as part of the request body which would prevent the need to make extra database calls to fetch that information.
Try to use Threads and Futures wherever possible. Multi-threading generally makes execution faster right!
You may also want to use caches at the API level. The data returned by APIs which is called frequently and which is generally not updated so frequently can be stored in the local cache of the server.
Handling Scale
Suppose all of a sudden you see a large influx of clients using your API. (After all, things tend to increase exponentially!). Your database and server have a certain limit on the number of connections. Your system was not designed to handle such a scale! Obviously, you would have to scale up your system, but in the meantime, as a hotfix, you could temporarily remove certain unimportant database calls or functions so that your API can still perform. This is a good thing to keep in mind while designing APIs.
Pagination

Pagination is a must. Suppose you are exposing an API that returns registered user details. Your system could have like 1,00,000 registered users. One way to go around this would be to fetch all the users from the database, process all their information, and send the result back over the internet. Well, there are lots of problems with this approach.
Sending so much data over the network would consume a lot of bandwidth.
Querying the database with so much data, sending, and processing it would increase the response time. (You don’t want your client to wait minutes for the response)
There are high chances the client would not even use all the info which he requested, which is a waste of resources.
There’s no way the client would show or use all the 1,00,000 user information at once. Using filters in the request body and pagination is the solution for it.
Using pagination, the API would query certain fragments of data (maybe 100 records) from the database and return those 100 records along with a token which the client can again use to fetch the next fragment (maybe the next 100 records). This way the response time is less, we are using only the information which is useful and it reduces complexity and load on resources.
Rate Limiting
Set rate limits — You may want to limit the number of API calls made by a user (or a token) within a given time frame. If a user exceeds that limit you throttle their request for that time period. There can be several reasons why you want to add rate limits —
prevents resource starvation
this is a way to keep a check that you are not denying service to other clients because one client is using your API a lot.
prevents malicious attacks like DDOS(Distributed Denial of Service) by hackers
You could rate limit programmatically or you could also charge clients some amount of money whenever they make an API call.

While I think the above rules contribute to good API designs, you may be in situations where you would need to compromise on certain design rules to make some other aspect of system more efficient. As a software developer it’s your responsibility to weigh the pros and cons and make a call. After all, designing systems are all about trade-offs (time vs space).



_edited.png)










































































Great post! I really enjoyed how clearly you explained the process of designing APIs and why proper structure is so important for scalability and usability. Many students studying software engineering often struggle to connect these real-world practices with academic theories. That’s why resources like computer science assignment help can be so useful, as they guide learners in applying concepts like API design to practical tasks. This kind of knowledge truly bridges the gap between theory and industry practice.
with interactive vr porn, you don’t just watch, you participate. step into virtual scenes that respond to your actions and voice. feel the thrill of being in control, as advanced technology makes adult content more immersive and personal than ever before. your fantasies are now within reach—digitally real and deeply engaging.
Experience thrilling restraint with sex handcuffs, designed for safe and exciting bondage play. Perfect for couples wanting to explore dominance and submission, these handcuffs add spice and control to intimate moments. Made with comfortable materials, sex handcuffs ensure pleasure without pain, enhancing trust and connection during adventurous encounters.
Discover unlimited entertainment on badwap com, where movies, music, and videos are just a click away. With a mobile-friendly interface, users can access trending content anytime, anywhere. Whether you’re into Bollywood hits or viral clips, this platform caters to every taste. Quick downloads and easy browsing make it a go-to site for digital fun.